
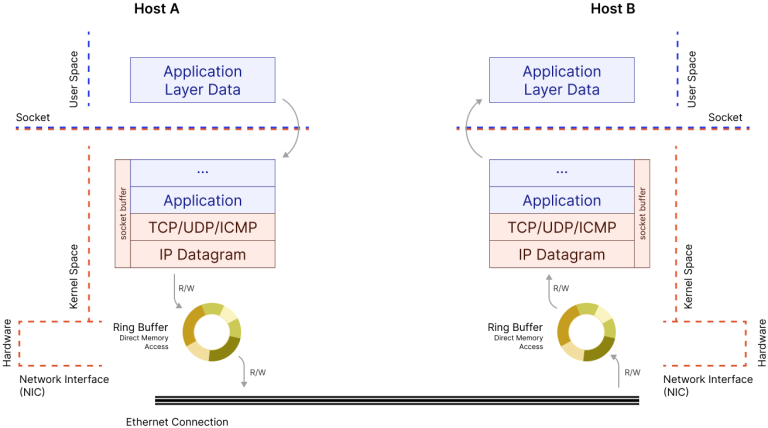
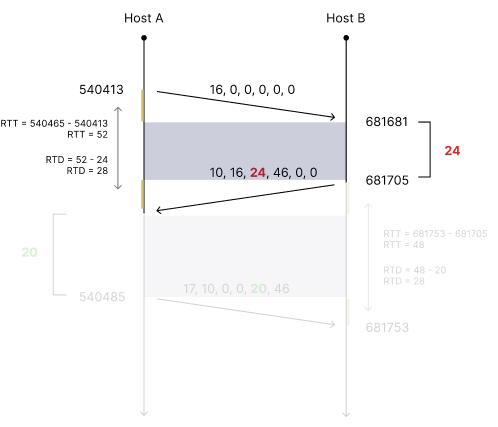
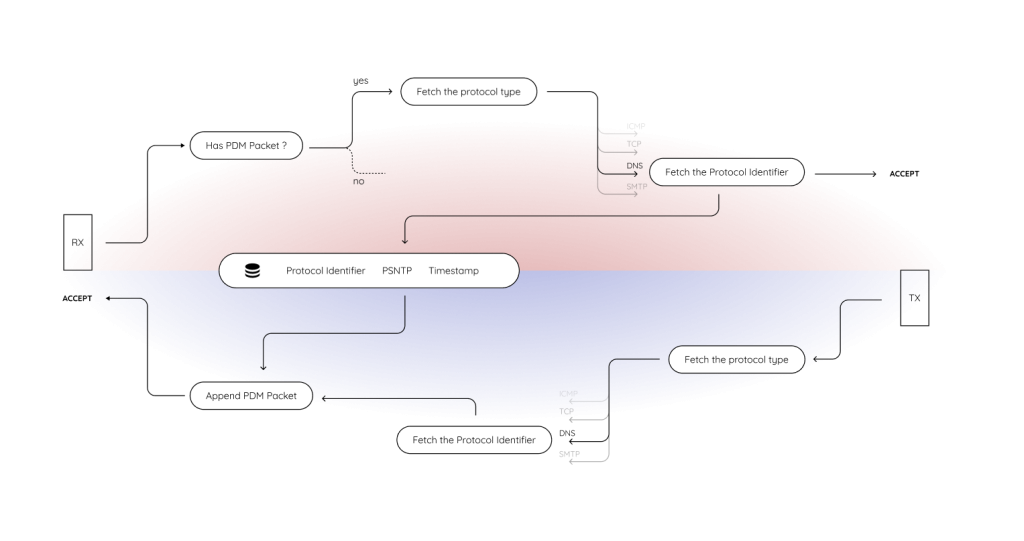
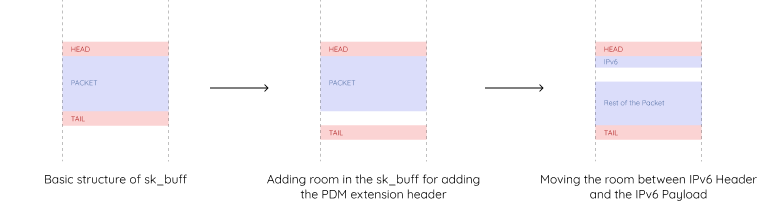

Both the server-side and client-side implementations are open source:
- Server-Side Kernel Module:
 https://github.com/indiainternetfoundation/IPv6PerformanceDiagnosticMetric
https://github.com/indiainternetfoundation/IPv6PerformanceDiagnosticMetric - Python Client Library:
https://github.com/indiainternetfoundation/py_measure_dns
India Internet Foundation (IIFON) actively welcomes contributions to these repositories – whether it’s code, testing, docs, bug reports, or feature ideas. These efforts are part of a broader national initiative to make the Internet stack more observable, efficient, and intelligent.


